Wstęp
Kiedyś dawno temu, na początku moje przygody i fascynacji uczeniem głębokim, zacząłem tworzyć definicję klasy obiektów, mającą posłużyć do szybszego i prostszego budowania modeli sieci w TensorFlow. Pomimo że było to dawno to nadal czuję, że jestem na początku mojej drogi w tej dziedzinie ale tamten moment to był początek początku. W międzyczasie odkryłem istnienie biblioteki Keras (nie jest to jedyny framework do uczenia głębokiego), czyli takiego właśnie gotowca do tworzenia modeli sieci neuronowych. Teraz jestem już trochę mądrzejszy i wiem, że w dziedzinie uczenia maszynowego bardzo wiele drzwi jest już pootwieranych i konstruowanie własnych łomów i taranów do ich wyważania po prostu mija się z celem. Jak to powiedział któryś z moich wykładowców prowadząc obliczenia numeryczne na AGH: „nie piszcie sami kodu do obliczeń i tak nie napiszecie go lepiej niż w ogólnie dostępnych bibliotekach”.
CIFAR-10
Skoro poczułem się trochę mądrzejszy to pozwoliłem sobie zmienić dotychczasowy zbiór danych do obróbki na bardziej złożony i trochę trudniejszy do przetworzenia. Do tego wpisu zamiast MNISTa wybrałem inny, powszechnie stosowany w edukacji i przykładach zbiór mikro zdjęć CIFAR-10. Jest to baza 60 000 kolorowych obrazów o rozmiarze 32×32 piksele wraz z etykietami przypisującymi je do 10 rozłącznych klas (airplane, automobile, bird, cat, deer, dog, frog, horse, ship, truck). Oba wspomniane zbiory są chyba najczęściej używana bazą do nauki inteligentnych algorytmów rozpoznawania obrazów. Poniżej 25 losowo wybranych obrazów ze zbioru treningowego wraz z ich etykietami.

Keras
Wracając do Keras, jest to wysokopoziomowe API napisane w Pythonie stanowiące wygodny framework do definiowania modeli używanych w uczeniu głębokim. Ma on możliwość uruchomienia pod sobą CNTK, Theano czy używanego przeze mnie googlowego TensorFlow. Już w samy TensorFlow otrzymujemy w module tf.keras dedykowaną implementację własną tego API, dlatego żeby zacząć go używać nie potrzeba instalować żadnych dodatkowych modułów:
>>> import tensorflow as tf >>> tf.keras.__version__ '2.1.6-tf' >>>
Jak piszą jego autorzy należy jedynie pamiętać o tym,
-
- że aktualna wersja tf.keras nie musi być zgodna z aktualną i oficjalną wersją Keras
-
- a kiedy zapisujemy wagi naszego modelu tf.keras domyślnie zapisuje je w formacie checkpoints zależnym od naszego kodu, który definiuje model. Jeżeli chcemy zapisać je w formacje HDF5 należy ustawić parametr save_format=’h5′.
Na początek
No to zaczynamy. Poniżej absolutne minimum, które jak zobaczymy, wcale nie jest najlepszym rozwiązaniem.
Co nam potrzeba:
import tensorflow as tf from tensorflow.keras import Sequential, layers from tensorflow.keras.datasets import cifar10 from tensorflow.keras.utils import to_categorical
Ustawienia zmiennych dla algorytmu:
batch_size = 128 epochs = 42 validation_split = 0.1
batch_size – wielkość paczki danych/obrazków w pojedynczej iteracji po której będzie wykonywana optymalizacja wartości błędu z użyciem gradientu. Inaczej, po takiej paczce nasz model będzie optymalizował wagi w sieci neuronowej.
epochs – ilość cykli, czyli ile razy przepuścimy obrazy przez naszą sieć.
validation_split – stosunek podziału naszego treningowego zbioru obrazków, na dane do uczenia i walidacji. W tym wypadku 10% obrazów użyjemy do walidacji skuteczności działania sieci w trakcie jej uczenia.
Wczytanie danych
Keras jest tak miłym narzędziem, że ma zaimplementowane gotowe dedykowane do załadowania zbioru CIFAR-10 funkcje. Nie musimy nawet podawać lokalizacji zbioru, gdyż funkcja potrafi sam pobrać potrzebne dane z sieci.
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
Funkcja load_data() zwraca dwa tuplety , w pierwszym otrzymujemy dane 50000 obrazów i ich etykiety które posłużą do trenowania sieci. W drugim tuplecie mamy zestaw 10000 obrazów do ostatecznego przetestowania naszego modelu. Dane otrzymane są w kształcie:
>>> x_train.shape (50000, 32, 32, 3)
Czyli 50000 obrazów 32×32 piksele w 3 warstwach, odpowiednio dla każdego koloru RGB.
Dane etykiet to z kolei 50000 jednoelementowych tablic z numerem etykiety odpowiadającej temu co jest na obrazie.
>>> y_train.shape (50000, 1) >>> y_train[0] array([6], dtype=uint8)
Przygotowanie danych
Na potrzeby naszego modelu zmienimy etykiety liczbowe na wektory „onehot” odpowiadające warstwie wyjściowej naszego modelu, który za chwilę zdefiniujemy. Wyjście sieci będzie miało 10 węzłów, po jednym dla każdej z klas obrazów i będzie aktywowane poprzez funkcje softmax. Funkcja ta ustawia wartość 1 dla najbardziej prawdopodobnej klasy rozpoznawanego obiektu i zero dla pozostałych. Tak więc etykiety zmienimy na 10-elementowe wektory w których każda współrzędna odpowiada odpowiedniej klasie. np. dla klasy 6 mamy: array([[0., 0., 0., 0., 0., 0., 1., 0., 0., 0.]], dtype=float32). W celu konwersji również możemy użyć gotowca, funkcji to_categorical z keras.utils
y_train = to_categorical(y_train, 10) y_test = to_categorical(y_test, 10)
Następnie wykonujemy normalizację danych, po której optymalizacja metodą gradientu będzie odbywała się o wiele sprawniej. Maksymalną wartością występującą w danych jest 255, czyli tyle ile można maksymalnie (uint8) przypisać do wartości pojedynczego koloru w RGB. Wystarczy podzielić wszystkie nasze dane wejściowe przez 255.
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
Definicja prostego modelu sieci konwolucyjnej
Teraz możemy przejść do właściwej definicji modelu. Zaczniemy od podejścia minimalnego, zbudujemy model jedynie w oparciu o dwie warstwy konwolucyjne. Tu powinna pojawić się długa dygresja co to jest i jak działają sieci konwolucyjne ale będą jedynie odnośniki do miejsc gdzie jest to lepiej opisane i zobrazowane niż sam byłbym w stanie to zrobić. Na przykład na jednym z lepszych polskich blogów o uczeniu maszynowym tworzonym przez Pana Krzysztofa Sopyłę https://ksopyla.com/python/operacja-splotu-przetwarzanie-obrazow/ . Tu z kolei http://scs.ryerson.ca/~aharley/vis/conv/ dostępne jest przewspaniałe narzędzie online, które pomaga zobaczyć jak taka sieć działa w praktyce, przez co łatwiej można zrozumieć idee jaka się za sieciami konwolucyjnymi kryje.
Bardzo ogólnie, warstwy konwolucyjne nakładają na obraz różne filtry, choć tu bardziej by mi pasował termin maski, które pomagają uwydatnić odpowiednie cechy na obrazie jak np. krawędzie obszarów. Mogą również wyostrzyć lub odpowiednio rozmyć obraz itp.
Definiujemy dwie pierwsze warstwy konwolucyjne w naszym modelu. Pierwsza będzie nakładać 32 filtry w rozmiarze 3×3 na obraz wejściowy, przesuwając je po jednym pikselu (domyślnie krok – stride – jest ustawiony na 1 w każdym kierunku). Jako funkcji aktywacji używamy ReLU. Padding określa zachowanie naszego filtra na brzegach obrazu, w naszym wypadku uzyskamy taki sam rozmiar wyjścia z warstwy jak dane wejściowe.
Druga warstwa ma 64 filtry nakładane na wyjście z warstwy pierwszej.
cnn_model = Sequential([ layers.Conv2D(32, (3, 3), padding='same', input_shape=(32,32,3), activation='relu'), layers.Conv2D(64, (3, 3), padding='same', activation='relu'),
Kolejna warstwa spłaszcza nasz 2-wymiarowy obraz do jednej linii 512 w pełni połączonych (fullconected) neuronów i to w tym miejscu obliczeń CPU/GPU może trochę podgrzać nam mieszkanie.
layers.Flatten(), layers.Dense(512, activation='relu'),
Ostatnią warstwę wyjściową tworzy 10 neuronów z funkcją aktywacji softmax, która wybiera 1 z 10 najbardziej prawdopodobną klasę obrazu.
layers.Dense(10, activation='softmax')])
Podsumowanie naszego modelu:
>>> cnn_model.summary() _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_2 (Conv2D) (None, 32, 32, 32) 896 _________________________________________________________________ conv2d_3 (Conv2D) (None, 32, 32, 64) 18496 _________________________________________________________________ flatten (Flatten) (None, 65536) 0 _________________________________________________________________ dense (Dense) (None, 512) 33554944 _________________________________________________________________ dense_1 (Dense) (None, 10) 5130 ================================================================= Total params: 33,579,466 Trainable params: 33,579,466 Non-trainable params: 0 _________________________________________________________________
Mamy ponad 33,5M parametrów, jak pisałem jest co liczyć ale i będzie można pewnie coś zoptymalizować.
Ustawiamy funkcje wyliczania błędu, algorytm jej minimalizacji i używaną metrykę. Następnie trenujemy model naszymi danymi 50000 obrazów z czego 5000 używamy do walidacji w trakcie procesu uczenia.
cnn_model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
history = cnn_model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_split=validation_split,
shuffle=True)
Całość wygląda tak:
import tensorflow as tf
from tensorflow.keras import Sequential, layers
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.utils import to_categorical
# Size of data batch per gradient update
batch_size = 128
# Number of training epochs
epochs = 42
# Validation split of training data to evaluate metrics such as loss
validation_split = 0.1
# Download and load Cifar-10 dataset
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# Make onehot vectors from data labels
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
# Convolutional neural network model
cnn_model = Sequential([
layers.Conv2D(32, (3, 3), padding='same', input_shape=(32,32,3), activation='relu'),
layers.Conv2D(64, (3, 3), padding='same', activation='relu'),
layers.Flatten(),
layers.Dense(512, activation='relu'),
layers.Dense(10, activation='softmax')])
# Print model summary
cnn_model.summary()
# Compile model
cnn_model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# Fit model with training data
history = cnn_model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_split=validation_split,
shuffle=True)
Nie wiem czy można by było coś więcej uprościć, poza użyciem modelu z jedną warstwą konwolucyjną (właśnie sprawdziłem, że też działa z ograniczoną dokładnością). Ale na tak wysokim poziomie abstrakcji jaki daje nam Keras, tylko tyle kodu wystarczy, żeby nauczyć komputer rozpoznawania obrazów przy użyciu uczenia głębokiego.
(Nie)działanie sieci w praktyce
A teraz cytując klasyków Internetów, „nie róbcie tego w domu”, chyba że chcecie się dogrzać, macie tani prąd i niepotrzebne cykle procesora 😉 Mój stary laptop z 4-rdzeniowym Intel(R) Core(TM) i5-2540M CPU @ 2.60GHz potrzebuje około 10 minut na jeden cykl/epokę przy tak zdefiniowanym modelu. Jak się ma cierpliwość i możemy zostawić udający suszarkę do włosów komputer na noc, to w efekcie uzyskamy sieć, która na zbiorze testowym będzie miała błąd loss:4.4617 i dokładność accuracy:0.6205.
In [13]: cnn_model.evaluate(x_test, y_test,
...: batch_size=batch_size)
10000/10000 [==============================] - 1s 65us/sample - loss: 4.4617 - acc: 0.6205
Out[13]: [4.461730474853516, 0.6205]
import matplotlib.pyplot as plt
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('Dokładność modelu')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'cv test'], loc='upper left')
plt.show()
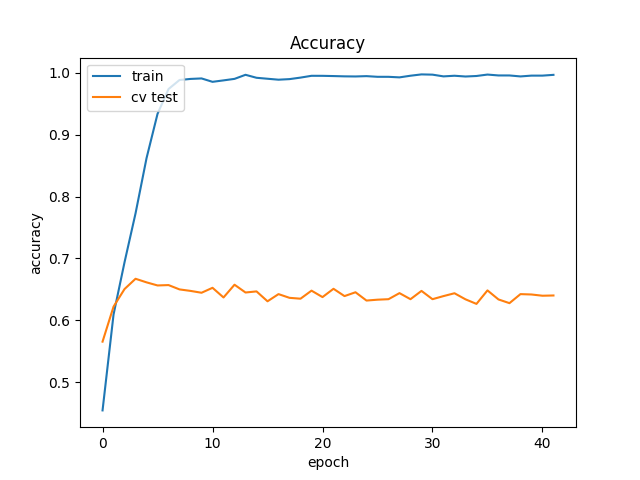
Już w trzeciej epoce uzyskujemy praktycznie maksymalną osiąganą dokładność, więc tu moglibyśmy algorytm spokojnie przerywać. Ale zamiast się zatrzymać doskonalimy nasz overfiting na zbiorze treningowym. Po 42 cyklach nasz algorytm praktycznie nauczył się „na pamięć” każdego przypadku z 45k obrazów w zbiorze treningowym, co wcale nie oznacza, że sobie dobrze poradzi z innymi obrazkami… 6 na 10 no tak średnio, bym powiedział.
Jak żyć? – zapytacie. Obrazki wielkości znaczka pocztowego, na których prawie nic nie widać, tyle czasu się to mieli, a na końcu prawidłowo rozpoznaje tylko 6 na 10 obrazków. W końcu mamy XXI wiek! Otóż można tą naszą sieć trochę okroić przez dodanie dodatkowych warstw redukujących tj. MaxPooling i Dropout, oraz spróbować poprawić jej skuteczność. Ale o tym jeszcze nie dziś.
Linki
- Część druga – prosta optymalizacja
- Dokumentacja modułu z TensorFlow: https://www.tensorflow.org/api_docs/python/tf/keras
- Opis użycia: https://www.tensorflow.org/guide/keras
- Dokumentacja framework’a: https://keras.io/
- Opis zbioru CIFAR-10: https://www.cs.toronto.edu/~kriz/cifar.html





Pingback: Rozpoznawanie obrazów CIFAR-10 – optymalizacja – Majcher.NET