W poprzednim wpisie opisałem jak zbudować najprostszy model do uczenia głębokiego z użyciem Keras, który to model nauczył się jako tako rozpoznawać obrazki ze zbioru CIFAR-10. Dziś spróbujemy trochę udoskonalić ten model. Wspomnę tu jeszcze, że od czasu ostatniego wpisu w moim środowisku obliczeniowym zaszła już jedna istotna optymalizacja, otóż mam nowy hardware do obliczeń. Liczę teraz na CPU Intel(R) Core(TM) i7-9700K CPU @ 3.60GHz i GPU GeForce RTX 2070 SUPER. Wynikiem czego więcej optymalizacji już nie potrzeba, sieć którą mój stary laptop trenował prawie całą noc, na nowym sprzęcie trenuję w niecałe 5 minut (274 sek. na 42 epoki). Oczywiście optymalizować można i nawet trzeba, bo poza dalszym skróceniem czasu możemy uzyskać także lepsze wyniki.
Pierwszą modyfikacją jaką wykonamy, to dołożenie zaraz za pierwszą warstwą konwolucyjną naszego modelu, warstwy MaxPooling, która zmniejsza rozdzielczość naszych obrazków uzyskanych po ich złożeniu z kolejnymi filtrami konwolucji. Jak działa warstwa MaxPooling2D? Po wejściowym obrazie przesuwamy okienko, w naszym przypaku 2 na 2 piksele, wybierając największą wartość z oglądanej czwórki. Przesuwając próbkujące okienko o jeden piksel po całym obrazie, uzyskujemy w wyniku obraz o zredukowanej o połowie w stosunku do poprzedniej warstwy rozdzielczości. W naszym wypadku uzyskujemy obrazy o wielkości 16×16.
Definicja modelu wygląda teraz następująco:
cnn_model = Sequential([
layers.Conv2D(32, (3, 3), padding='same', input_shape=(32,32,3), activation='relu'),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, (2, 2), padding='same', activation='relu'),
layers.Flatten(),
layers.Dense(512, activation='relu'),
layers.Dense(10, activation='softmax')])
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_10 (Conv2D) (None, 32, 32, 32) 896 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 16, 16, 32) 0 _________________________________________________________________ conv2d_11 (Conv2D) (None, 16, 16, 64) 8256 _________________________________________________________________ flatten_5 (Flatten) (None, 16384) 0 _________________________________________________________________ dense_10 (Dense) (None, 512) 8389120 _________________________________________________________________ dense_11 (Dense) (None, 10) 5130 ================================================================= Total params: 8,403,402 Trainable params: 8,403,402
Zmniejszamy w ten sposób ilość parametrów naszej sieci z 33M do 8M dzięki czemu czas obliczeń (przy 42 epochs) spada do 156 sekund. Co ciekawe poprawia nam to również wynik uzyskany na zbiorze testowym na loss: 2.9567 i acc: 0.6670
Kolejną warstwą stosowaną powszechnie w modelach sieci konwolujcyjnych, a której jeszcze nie mamy w tym modelu jest warstwa Dropout. Ta warstwa usuwa losowo wybrane parametry przekazywane do wejścia następnej warstwy. W naszym wypadku usuniemy na początek losowo 1/4 wartości na kolejnych wejściach. Wynikiem takiego działania jest dalsze zmniejszenie liczby parametrów obliczanych dla naszej sieci ale co ważniejsze, takie losowe zmiany struktury powodują również to, że nasza sieć będzie mniej podatna na przeuczenie na zbiorze treningowym. Model wygląda teraz tak:
cnn_model = Sequential([
layers.Conv2D(32, (3, 3), padding='same', input_shape=(32,32,3), activation='relu'),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Dropout(0.25),
layers.Conv2D(64, (2, 2), padding='same', activation='relu'),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dropout(0.25),
layers.Dense(512, activation='relu'),
layers.Dropout(0.25),
layers.Dense(10, activation='softmax')])
I rzeczywiście dokładność modelu na zbiorze treningowym rośnie zdecydowanie wolniej a na zbiorze testowym uzyskujemy wynik loss: 1.1138 i acc: 0.7089.
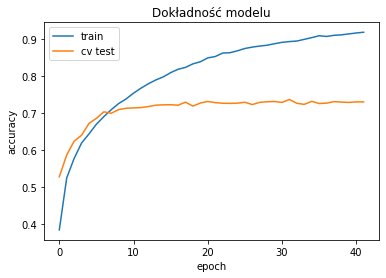
Z takim zestawem warstw można kombinować i szukać najlepszego modelu. Na początek dodałem trzecią warstwę konwolucyjną i pokombinowałem z parametrami pozostałych warstw i otrzymałem loss: 0.6516 i acc: 0.7973 na poniższym modelu:
cnn_model = Sequential([
layers.Conv2D(32, (3, 3), padding='same', input_shape=(32,32,3), activation='relu'),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Dropout(0.3),
layers.Conv2D(64, (3, 3), padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Dropout(0.3),
layers.Conv2D(128, (3, 3), padding='same', activation='relu'),
layers.Dropout(0.5),
layers.Flatten(),
layers.Dense(512, activation='relu'),
layers.Dropout(0.5),
layers.Dense(10, activation='softmax')])
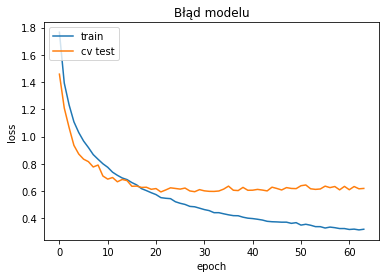
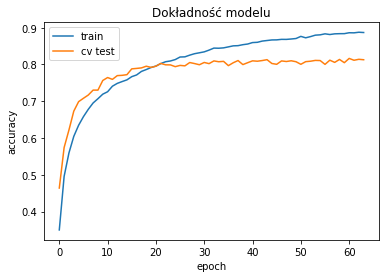
Wynik końcowy nie jest idealny i w sieci można znaleźć lepsze modele ale jest skutkiem jednego wieczoru i kilkunastu uruchomień algorytmu. Pomyśleć, że jeszcze kilka miesięcy temu wymagałoby to kilkunastu nocy. Tak, inwestowanie w sprzęt ma sens bo realnie oszczędza czas, pomimo że wręcza nas od myślenia i optymalnego projektowania algorytmów. Takie czasy.





Pingback: Rozpoznawanie obrazów z CIFAR-10 z użyciem Keras – Majcher.NET